
Seth van Hooland, Ruben Verborgh, Max De Wilde
このチュートリアルでは、研究者がどのようにしてデータの正確性を診断し、それに基づいて行動するかに焦点を当てています。
目次
レッスンの目標
データを額面通り受け止めてはいけません。これが、研究者がどのようにしてデータの正確性を診断し、それに基づいて行動するかに焦点を当てたこのチュートリアルのキーメッセージです。本レッスンでは、データクリーニングの原則や実践について学び、OpenRefineを使って行える、データのクリーニングにおいて欠かせない以下の4つのタスクについて説明します:
- 重複レコードの削除
- 同一フィールド内の複数の値の分割
- データセット全体での値の分布の分析
- 同じ事象に対する別表現のグルーピング
これらのステップは、パワーハウスミュージアムが提供しているメタデータコレクションに基づいた演習に沿って解説しており、(半)自動化した方法がどのようにデータ内のエラーを修正できるのかを示しています。
歴史研究者はなぜデータの質を気にするべきなのか
重複しているレコードや空白値、フォーマットの不統一などに対しては、過去のデータセットを扱う際に備えていなければなりません。本レッスンでは、スプレッドシートやデータベース内に含まれている矛盾したデータを見つける方法を解説します。ウェブ上でデータを共有したり集約したり再利用したりすることが増えている中で、歴史研究者は、避けては通れないデータ品質の問題に対処しなくてはならないでしょう。OpenRefineというプログラムを使えば、空白セル、重複レコード、表記ゆれなどのシステマティックなエラーを簡単に特定できるようになります。OpenRefineはデータの精度について素早く診断できるようにするだけでなく、処理を自動化することで特定のエラーに対応できるようにしてくれます。
OpenRefineの概要
これまで歴史研究者は、データの質を判断しデータのクリーニングを実施するためには、情報技術の専門家に頼らなくてはなりませんでした。データセットの規模が大きければ、カスタマイズされたコンピュータープログラムを用いる必要があったのです。幸運なことに、インタラクティブ・データ変換(Interactive Data Transformation; IDT)ツールの出現により、深いスキルをもたない専門家でも大量のデータを高速かつ安価に操作できるようになったのです。
IDTは、私たちがよく知っているデスクトップ版の表計算ソフトに似ていて、機能も共通している部分があります。例えば、マイクロソフトのExcelなどのアプリケーションでは、数値、アルファベット、または独自フィルターによってデータを並べ替えて、容易にエラーを見つけ出すことができます。しかし、このようなフィルター機能は二次的なものなので、その設定を表計算で行うのは面倒かもしれません。もっと一般的なレベルで言うと、表計算は個別の行やセルを扱うように設計されているのに対し、IDTは一度に大量のデータを扱うように設計されていると言えます。これらの「ステロイド上のスプレッドシート」は、使いやすい統合インターフェイスを提供し、エンドユーザーがエラーを見つけ出して修正できるようにしています。
近年、IDTのための汎用ツールが開発されており、例えば Potter’s Wheel ABC や Wrangler などがあります。ここでは特に OpenRefine (以前はFreebase GridworksやGoogle Refineと呼ばれていたもの)に注目していきます。これは、ブラウザベースのインターフェイスを通じて、大量のデータを効率的にクリーニングするツールとして、最も使いやすいものであると考えているからです。
データプロファイリングとクリーニング操作に加え、OpenRefineの拡張機能を使うことで、非構造化テキストにおける概念を、固有表現抽出 (named-entity recognition; NER)と呼ばれる処理を通じて特定し、既存の知識ベースと自分のデータを照合することもできます。そうすることで、OpenRefineは、米国議会図書館やOCLCなどの機関によってウェブ上で既に宣言されている概念や典拠情報に対し、データを紐づけることができる実践的なツールとして機能するのです。データクリーニングはそれらのステップのため前提であり、NERの成功率とあなたのデータと外部典拠データとの間のマッチング成功率は、データを首尾一貫したものにできるかどうかにかかっています。
演習の概要: パワーハウスミュージアム
シドニーのパワーハウスミュージアムは、コレクションに関する自由利用可能なメタデータをウェブサイト上で提供しています。同博物館は世界でも最大規模の科学技術博物館であり、蒸気機関からガラス細工品やオートクチュール品、コンピューターチップまで、90,000点を超える資料へのアクセスを提供しています。
パワーハウスミュージアムは、そのコレクションのオンライン公開を非常に積極的に行っており、データのほとんどを自由に利用できるようにしています。博物館のウェブサイトからは、ファイル名がphm-collection.tsvとなっているタブ区切りのテキストファイルをダウンロードでき、表計算ソフトで開くことができます。解凍後のファイル(58MB) には75,823点もの資料に関する基本的なメタデータ(17フィールド)が含まれており、Creative Commons Attribution Share Alike (CCASA) ライセンスの下で公開されています。本チュートリアルでは、筆者らが保存して(この後すぐに)あなたがダウンロードできるようにしたデータのコピーを使います。これにより、パワーハウスミュージアムがデータを更新しても、レッスンに沿って学習を進めることができます。
データプロファイリングやデータクリーニングのプロセスを通じて、本ケーススタディでは、特にパワーハウスミュージアムの資料名シソーラス(Powerhouse Museum Object Names Thesaurus; PONT)の用語が使われている Categoriesフィールドに注目します。PONTはオーストラリア英語特有の言葉遣いや綴りを認識し、コレクションの強みを非常に直接的に反映しています。コレクションは、社会史や装飾美術をよりよく表しており、一方で美術や自然史に関連する資料名は比較的少なくなっています。
Categoriesフィールド内の用語は、統制語彙と呼ばれるものを構成しています。統制語彙とは、限られた数の用語を用いてコレクションの内容を記述するキーワードで構成されているもので、図書館や文書館、博物館で、歴史研究者が触れるデータセットへの重要な入り口となっていることが多いです。「Categories」フィールドに注目しているのはこのためです。一旦データのクリーニングが完了すると、統制語彙の用語を再利用して、オンラインで用語に関する追加情報を見つけることが可能となります。これはLinked Dataの作成として知られているものです。
はじめに: OpenRefineのインストールとデータのインポート
OpenRefineをダウンロードし、インストール手順に従ってください。OpenRefineは、Windows、Mac、Linuxのすべてのプラットフォームで動作します。OpenRefineはブラウザーで開きますが、アプリケーションはローカルで実行され、データはオンラインで保存されないことを覚えてきましょう。データファイルは、FreeYourMetadataウェブサイトから入手可能で、本チュートリアルを通じて活用していきます。次へ進む前にphm-collection.tsvファイルをダウンロードしておいて下さい(the Programming Historianサイト上でもphm-collectionとして保存しています。)。
OpenRefineのスタートページで、ダウンロードしたデータを使用して、新規プロジェクトを作成し、「次へ」をクリックして下さい。デフォルトでは、最初の行はカラム名として正しく解析されますが、ファイル内の引用符はOpenRefineにとって何の意味もないため、「文字 ” でセルを囲む」のチェックボックスを外す必要があります。さらに、「セルのテキストを解析 数字, 日付…」のチェックボックスを選択すると、OpenRefineが自動で数値を検出するようになります。ここで「プロジェクトを作成」をクリックします。すべてうまくいけば、75,814行が確認できるでしょう。また、初期のOpenRefineプロジェクトを直接ダウンロードすることもできます。
パワーハウスミュージアムのデータセットは、タイトル、内容記述、アイテムが属する複数のカテゴリー、出所情報、博物館のウェブサイト上の資料への永続的なリンクを含む、すべてのコレクション資料に関する詳細なメタデータで構成されています。メタデータがどの資料に対応しているかを知るには、永続的なリンクをクリックすればウェブサイトが開きます。

データを知ろう
まずは、データを眺め、慣れ親しむことです。「ファセット」で表示することで様々なデータ値を確認することができます。ファセットは、選択した基準に基づいてデータの特定のサブセットを見るレンズのようなものと考えてください。カラム名の前の三角形をクリックし、ファセットを選択して作成します。例えば、フィールドに含まれている値の性質にもよりますが、テキストファセットや数値ファセットなどを試してみてください(数値は緑色で表示されます)。ただし、テキスト型のファセットは、冗長な値があるフィールド(例えばカテゴリー)に最適であることに注意してください。「選択肢が多すぎ、表示できません」というエラーが出たら、選択肢の上限をデフォルトの2,000件より増やすこともできますが、多すぎるとアプリケーションの動作が遅くなってしまいます(通常は5,000くらいでよいでしょう)。数値型のファセットにはこのような制限はありません。さらに多くのオプションを使いたい場合は「カスタムファセット」を使ってください。例えば、空白によるファセットは、各フィールドに値がいくつあるのか確認したい場合などに便利です。以下の演習を通じてこれらのファセットにさらに詳しく触れていきます。
空白の行を削除
レコードID列用に数値ファセットを作成した際に気が付いたと思いますが、空白の行が3行あります[訳注:RecordIDで数値ファセットを選択した際に”Non-numeric”として表示される3件のこと]。「数字」のチェックボックスを外し、非数値型の値のみを残すことで見つけることができます。実は、これらの値は空白ではなくスペース1個分の文字を含んでおり、値があるはずのところへカーソルを移動させると現れる「edit」(編集)ボタンをクリックすることで確認できます。これらの行を削除するためには、最初の列「全て」にある三角形をクリックして、「行を編集」を選択し、「マッチした行を削除」をクリックしてください。数値ファセットを閉じると、残りの75,811行が確認できます。
重複レコードの削除
第2のステップは重複レコードを見つけだし削除することです。これらは固有値、例えばレコードID(ここでは各エントリーに対してレコードIDが実際に固有であると仮定しています)などでソートすることで洗い出すことができます。この作業はレコードIDの左隣にある三角形をクリックし、「ソート…」を選択したのち、「数字」を選択することで実施できます。OpenRefineでは、並び替えを永続的に保存しない限り、並び替えは見やすくするためのものでしかありません。これを行うには、上部に現れた「ソート」メニューをクリックし、「行を永続的に並び替える」を選択してください。これを忘れると、本チュートリアルの後半で予期しなかった結果になってしまうでしょう。
これで同じ行が隣接するようになりました。次に、上の行と同じレコードIDをもつ行のレコードIDを空白にして、重複レコードとしてマークします。そのために、レコードIDの三角形をクリックし、「セル編集 >下方向に空白にする」 と選択してください。ステータスメッセージには、84列が編集されたことが表示されます(行の並び替えを恒久化することを忘れた場合は19行しか表示されません。その場合は「取り消す/やり直す」タブでブランクダウンの操作を元に戻し、前の段落へ戻って、行が並べ替えられただけではないことを確認してください)。レコードID列で「空白セル」のファセットを作成し(「ファセット > カスタムファセット > 空白ファセット(null/空))、「true」をクリックすることで84行の空白行を選択し、「全て」の三角形を押してこれらの行を削除してください(行を編集 > マッチした行を削除)。ファセットを閉じると、75,727行のユニーク行を確認できるでしょう。
重複レコードを削除するときは特に注意が必要です。上記のステップでは、データセットにユニークな値を持つフィールドがあると仮定していますが、これは行全体が重複していることを前提にしています。これは必ずしもそうとは限らないので、深く注意を払いつつ、行全体が重複レコードであるかどうかを手動で確認すべきです。
個別化(Atomization)
重複レコードを削除したので、Categoriesのフィールドを詳しく見ていくことができるようになりました。 平均して、各資料には2.25個のカテゴリーが紐づいています。これらのカテゴリーは、パイプ文字「|」で区切られた、同じフィールド内に含まれています。例えばRecord 9には、「Mineral samples|Specimens|Mineral Samples-Geological」という3つの値が含まれています。これらのキーワードの使用を詳細に分析するためには、Categoriesフィールド内の値を、パイプの位置で個別のセルに分割していく必要があります。これにより、75,727個あるレコードは170,167行に拡大します。(Categoriesにある三角形から)「セル編集>多値のセルを分割」を選択し、(「文字で分割」の)「区切り文字」に「|」を入力します。これで170,167行となったことがOpenRefineから通知されます。
行/レコードのパラダイムをよく理解しておくことは重要です。レコードID列を表示させ、何が起きているかを見てみましょう。列のヘッダーの上にあるラベルのリンクをクリックすることで、「行」と「レコード」の表示を切り替えることができます。「行ビュー」では、各行が2~3のレコードIDが、1つのカテゴリーを表しており、それぞれを個別に操作できます。「レコードビュー」にはレコードIDごとにエントリーがあり、行ごとに異なるカテゴリー(グレーまたは白でグループ化)を持つことが出来ますが、各レコードは全体として操作されます。具体的には、現在170,167個のカテゴリーの割り当て(行)があり、75,736個のコレクションアイテム(レコード)にまたがっています。元の75,727件のレコードと比べ9件増えていることに気が付いたかもしれませんが、この小さな違いについては後で触れるので、今は気にしないでください。
ファセットとクラスタリング
フィールド内の内容を適切に個別化すると、フィルターやファセット、クラスターを利用して、メタデータの古典的な問題を迅速かつ簡単に概観することができます。(Categoriesの三角形から)「カスタムファセット>空白ファセット」を適用することで、461件のレコードにはカテゴリーが割り当てられておらず、コレクションの0.6%を占めていることがすぐに分かるでしょう。フィールドにテキスト型ファセットを適用すると、コレクションに用いられている4,934個の異なるカテゴリーの概要を確認できます(デフォルトのリミットは2,000個なので、「カウンタを制限してください」をクリックして5,000まで上げることができます)。見出しはアルファベット順またはカウント(頻度)順に並び変え、コレクションのインデックス化を行うために最も頻繁に使われている用語の一覧を得ることができます。(カウント順に並べた場合)見出しの上位3つは「Numismatics」(8,041)、「Ceramics」(7,390)、「Clothing and dress」(7,279)です。
ファセットを適用すると、OpenRefineは様々な類似性によってファセットの選択肢をクラスターとしてまとめることを提案してきます[訳注:Categoriesのテキストファセットに「クラスタ」と表示されたボタンが登場するので、それをクリックする]。図2が示しているように、クラスタリングにより大文字小文字の不一致や単数形と複数形のばらばらな使い方、単純なスペルミスなどの問題に対応できるようになります。OpenRefineは関連する値を表示し、最も頻度の高い値へとマージするように提案してくれます。クラスタリングしたい値のボックスを個別に選択するか、最下部の「全選択」をクリックして選択し、「マージし再クラスタリング」を選択します。
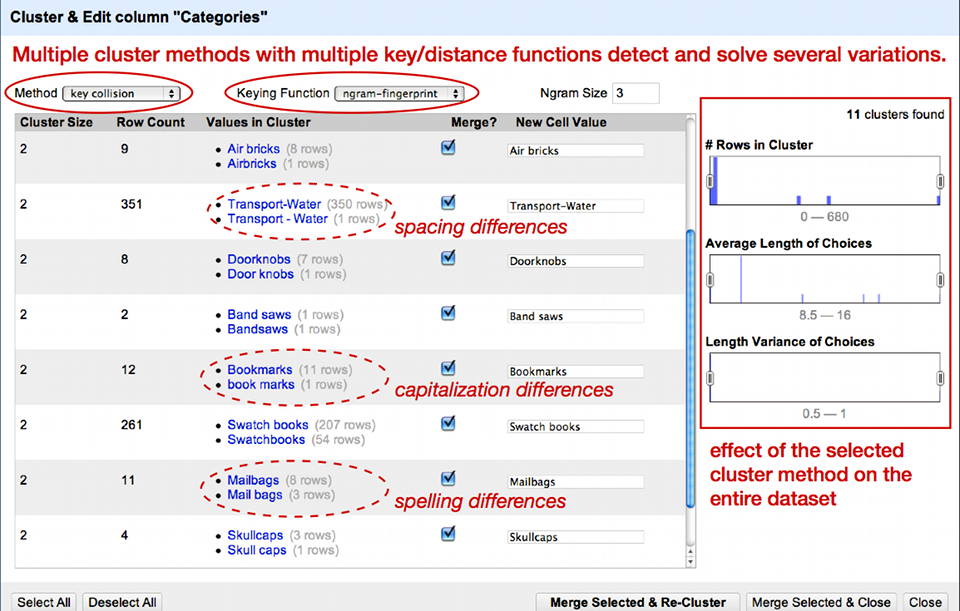
デフォルトのクラスタリング方法はあまり複雑ではないため、全てのクラスターを見つけ切れていません。様々な方法を試してみて、どのような結果が得られるか確認してください。ただし、方法の中にはアグレッシブすぎるものもあるため、一緒に属していない値をクラスタリングしてしまうかもしれないので注意してください。値が個別にクラスタリングされたので、それらを一つのセルに戻すことができます。Categoriesの三角形をクリックして「セル編集>多値のセルを結合」と選択してOKと押してください。区切りにはパイプ文字(|)を選択します。これで行は以前のようになり、Categoriesフィールドに複数の値が含まれていることでしょう。
正規表現を利用したアドホックな変換
分割処理の後にレコードの数が増えたことを覚えているでしょうか。どこからともなくレコードが9つ現れました。この差異の原因を見つけるためには、時間を巻き戻してカテゴリーを別々の行へと分割する前まで遡らなくてはいけません。そのために、(画面左上部にある)「ファセット/フィルター」タブの右隣にある「取り消す/やり直す」タブを押すと、プロジェクトを作成して以来あなたが行ってきた操作履歴を確認できます。「Split multi-valued cells in column Categories」より直前のステップを選択し(筆者の例に従ってきたのであれば、「Remove 84 rows」のはずです)、「ファセット/フィルター」タブに戻ってください。
この問題はパイプ文字の分割処理中に発生したので、ここで起きた問題はこの文字と関連しているのではないでしょうか。Categoriesカラムに対して、メニューから「テキストフィルター」を選択し適用してください。まずは左のフィールドに|と入力してください。75,727件あるレコードのうち、71,064件が一致(つまり、パイプ文字を含むレコード)していることをOpenRefineが教えてくれるでしょう。パイプ文字を含まないセルは、空白セルか、レコード#29のように「Scientific instruments」しか含んでいないような、区切りがなくカテゴリーが1つしかないセルなのです。
最初に入力したパイプ文字に続き|を入力し、||(ダブルパイプ)にしてください。このパターンに一致するレコードが9件あることが分かるでしょう。この9件のレコードが不一致の原因なのではないでしょうか。OpenRefineがこれらのレコードを分割した際、ダブルパイプを意味のないダブル区切りではなく2件のレコードの間における区切りとして解釈してしまったのでしょう。これらの値はどのように修正すればよいでしょうか?「Categories」フィールドのメニューから「セル編集 > 変換…」を選択してください。カスタムテキストによる変換インターフェイス(訳注:「式による値の変換」)へようこそ。これは、OpenRefine Expression Language(GREL)を使ったOpenRefineの強力な機能です。
以下に見える通り、テキストフィールド内の”value”という単語は、各セルの現在の値を表しています。この値に関数を適用することで、値を修正することができます(機能一覧はGRELドキュメンテーション(英語)を参照してください)。ここでは、ダブルパイプをシングルパイプに置換したいのです。これは以下の正規表現を使えば実現できます(引用符を忘れないでください)。
value.replace('||', '|')
「Expression」テキストフィールドの下で、ダブルパイプを削除して修正した値のプレビューを確認できます。OKをクリックしてから、(Categoriesの)「セル編集 > 多値のセルを分割…」からカテゴリーを分割してみると、今度はレコードの数が75,727のままになっているでしょう(再確認するために、「レコードビュー」をクリックしてみてください)。
* * *GRELで解決できるもう1つの問題が、同じカテゴリーが2回記述されているレコードの問題です。例えばレコード#41を見ると、「Models|Botanical specimens|Botanical Specimens|Didactic Displays|Models」といったカテゴリーがあります。「Models」カテゴリーは特に理由もなく2回記述されているので、重複している分を削除したいところです。Categoriesの▽をクリックし、「セル編集 >多値のセルを結合…」を選択し、OKをクリックしてください。区切りにはパイプ文字を選択してください。これで先ほどと同じようにカテゴリーが一覧表示されました。次に、Categoriesから「セル編集 > 変換」と選択してください。GRELを使ってパイプ文字でカテゴリーを1つずつ分割し、ユニークなカテゴリーを見つけて結合しなおすことができます。このためには、以下の通り入力してください。
value.split('|').uniques().join('|')
セルが33,008個、つまりコレクションの半分以上が影響を受けたことになります。
整形済みデータの出力
OpenRefineにデータを最初にロードして以来、全てのクリーニング操作はソフトウェアのメモリ内で実行され、元のデータはそのまま残されています。クリーニング済みのデータを保存したい場合は、画面右上の「出力」メニューをクリックして出力する必要があります。OpenRefineではCSVやHTML、Excelといった様々なファイル形式をサポートしているので、あなたのニーズに合った形式を選択するか、「テンプレート…」をクリックして独自のエクスポート用テンプレートを追加することができます。また、プロジェクトを他の人と共有するために、プロジェクトをOpenRefineの内部フォーマットで出力することもできます。
整形済みデータの次のステップ
一旦データがきれいになったら、次のステップへ進みOpenRefineの他のエキサイティングな機能を探索してみましょう。OpenRefineのユーザーコミュニティは特に2つの興味深い拡張機能を開発しました。それによって既にWebで公開されているデータとあなたのデータをリンクさせることができるようになっています。RDF Refine拡張機能はプレーンテキストのキーワードをURLへ変換してくれます。また、NER拡張機能は固有表現抽出(NER)を適用し、テキストからキーワードを特定しそれにURLを与えることができます。
終わりに
本レッスンで覚えておくべきことがあるとすれば、それは次のことです。すなわち、全てのデータは汚いものの、対応することはできるということです。ここで示したように、データの品質を大幅に上げるためにできることは多いのです。まず、データセットに含まれている空白値がいくつあり、ある特定の値(キーワードなど)がコレクション全体でどのくらいの頻度で使用されているかを簡単に把握する方法を学びました。このレッスンでは、OpenRefineを利用して重複やスペルの不一致などの繰り返し発生する問題を自動で解決する方法も紹介しました。OpenRefineでは、データセットのコピーで作業を実施しているだけでなく、エラーが発生した際にはステップをさかのぼることができるので、ためらうことなく色々とクリーニング機能を試してみてください。
著者について
Seth van Hooland氏はブリュッセル自由大学の情報通信科学部の准教授です。
Ruben Verborgh氏はゲント大学マルチメディアラボに所属するポスドク研究員です。
Max De Wilde氏はブリュッセル自由大学情報通信科学部の博士課程の学生です。
引用の際はこちらをご利用ください
<原著>
Seth van Hooland, Ruben Verborgh, and Max De Wilde, “Cleaning Data with OpenRefine,” The Programming Historian 2 (2013), https://programminghistorian.org/en/lessons/cleaning-data-with-openrefine.
<翻訳記事>
Seth van Hooland, Ruben Verborgh, and Max De Wildet著. 菊池信彦訳. OpenRefineでデータをきれいにする方法. 東アジアDHポータル. 2019. https://www.dh.ku-orcas.kansai-u.ac.jp/?p=468.

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。