Stephen Krewson
HathiTrustとInternet Archiveによる機械学習とAPIの拡張機能によって、デジタル化資料のなかから、視覚的に関心のあるページ領域を簡単に抽出できるようになりました。このレッスンでは、これらの領域を効率よく抽出し、それによって新しい視覚的な研究課題へ取り組む方法を紹介します。
目次
概要
もし本の中の挿絵だけ見たかったら、どうすればいいだろう?この疑問は、小さい子供も大人の研究者も思いつくものです。本が電子図書館から入手可能だと分かっているとすれば、挿絵のあるページだけをダウンロードして他のページを無視できるとありがたいでしょう。
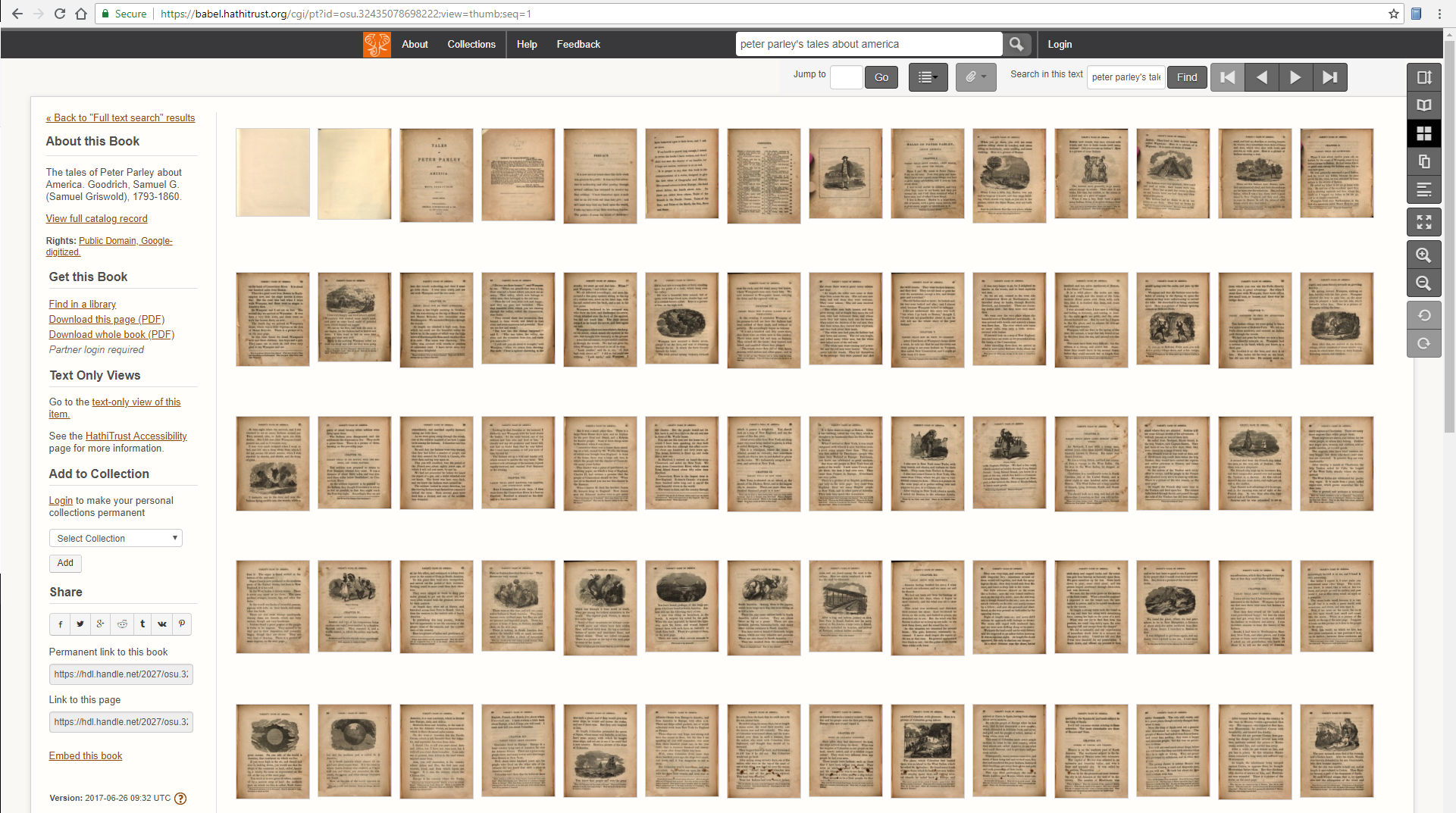
以下は、HathiTrustで識別子osu.32435078698222を持つ資料のページサムネイルです。このレッスンプロセスの後、挿絵のあるページのみ(合計31ページ)がJPEGファイルとしてフォルダにダウンロードできました。

「挿絵のない」ページがどれだけ取り除かれたのかを見るには、児童文学のベストセラー、Samuel Griswold Goodrichの『ピーター・パーレーのアメリカ物語(Tales of Peter Parley about America)』(1827年初版)の1845年改訂版全148ページのサムネイルと比較してみるとよいでしょう。
このレッスンは、世界最大級の2つの電子図書館、HathiTrust (HT)とInternet Archive (IA)が公開しているパブリックドメインの書籍から、このようなページの抽出とダウンロードを行うための手法を紹介します。挿絵と本のレイアウト(mise en page)の歴史を知るために画像コーパスを作りたい人にとっては、興味あるものとなるでしょう。EBBAとAIDAの先駆的取り組みにつづいて、デジタル書誌学への視覚的アプローチが人気を集めています。最近完了した、あるいは、研究資金を得た2つのプロジェクトの例を挙げると、脚注の特定や傍注の追跡の方法を開発するものもあります。
私自身の研究は、19世紀の医学書や教育書の挿絵の頻度や様式の変化に関して経験的な問題に答えようとするものです。これには、本ごとの挿絵の数を集計し、これらの挿絵を作るのにどのような印刷工程が行われたのかを推察する必要があります。挿絵のページ抽出のおそらくより的確なユースケースは、同じ本の異なる版での挿絵の対照調査です。今後の研究では、抽出した画像の視覚的な特徴や「意味」(色、大きさ、テーマ、ジャンル、挿絵の数など)を有益に調査することになるでしょう。
関心のある領域のなかからさらに絞り込んで情報を抜き出すには、かなりの機械学習を必要とする過程なので、このレッスンの範囲を超えています。しかし、挿絵がある(あるいはない)ページのYes/No分類は、対象コレクションのそれぞれの本の「すべての」ページ、という膨大なスペースを狭めるうえでの最初の実用的なステップであり、それにより挿絵の絞り込み(localization)を可能とするものです。参考として、19世紀の医学書では(平均して)ページの1~3%に挿絵があります。つまり、仮に前提知識がない電子図書館コーパス内の挿絵を研究しようとすると、コーパスの90%以上のページには挿絵が「ない」と仮定できるのです。
HathiTrustとInternet Archiveは、光学的文字認識ソフトウェア(OCRは紙の本をスキャンした後に施され、しばしばノイズの多いテキストデータが作られます)を使って生成されたデータを解析することで、挿絵のあるなしの問題に答えることが可能です。OCRによるデータを活用して挿絵のページを見つけるというのは、Kalev Leetaruが2014年にInternet ArchiveとFlickrとの共同研究で最初に提案したものでした。このレッスンでは、LeetaruのアプローチをHathiTrustに移し、PythonのXML高速処理ライブラリと、最近幅広くなったInternet Archiveの画像ファイル形式を活用します。
HTとIAはOCRで抽出した情報を少し異なる方式で公開しているため、各ライブラリの「視覚的な特徴」の詳細については、それぞれの節で述べることとします。
目標
このレッスンの後、あなたは
- Anacondaの「最小限」のPythonディストリビューション(Miniconda)をセットアップして、環境を構築できるようになります
- 検索によって生成されたHTまたはIAの書籍IDのリストを保存し、反復処理を行うことができます。
- HTとIAデータのアプリケーション・プログラマ・インターフェイス(API)にPythonのライブラリを通じてアクセスできるようになります。
- ページレベルでの見た目の特性を見つけることができるようになります。
- プログラミングによってページのJPEGファイルをダウンロードができるようになります。
より大きな目標は、歴史的な挿絵のコーパスを作成することで、データ収集と探索スキルを高めることにあります。画像データと書籍メタデータを合わせることで、時間を通じて視覚的な変化を考察するという意義のある研究課題を立てることが可能になるでしょう。
必要な要件
このレッスンのソフトウェア要件は最小限のもので、標準的なOSが動作するコンピュータとウェブブラウザです。Minicondaは、Windows、macOS、Linuxのそれぞれ32ビット、64ビット版で利用可能です。Python 3が現在の安定版であり、無期限でサポートされています。
このチュートリアルは、コマンドラインとPythonの基礎知識を前提としています。シェルベースチュートリアルにおけるコメントとコマンドの規則の理解が必要です。コマンドラインスキルのブラッシュアップには、Ian MilliganとJames Bakerによる「Bashコマンドライン入門」をお勧めします。
セットアップ
依存関係
より経験豊富な読者は、単に依存関係をインストールし、選択した環境でノートブックを実行したいかもしれません。私のMinicondaのセットアップ(およびWindowsとUnix系の違い)についての追加情報を提供します。
- hathitrust-api (インストールはこちら)
- internetarchive (インストールはこちら)
- jupyter (インストールはこちら)
- requests (インストールはこちら) [作成者はpipenvでのインストールを推奨しています。pipについてはPyPIを参照。]
レッスンファイル
こちらの圧縮フォルダをダウンロードしてください。これは、HTとAIそれぞれの電子図書館に対応する2つのJupyter Notebookを含んだものです。また、フォルダには、HathiTrustのコレクションを記述したJSONメタデータのサンプルも含まれています。解凍して以下のファイルがあることを確認してください: 554050894-1535834127.json, hathitrust.ipynb, internetarchive.ipynb.
以下の全てのコマンドは、レッスンファイルを格納したフォルダがカレントディレクトリとなっていることを想定したものです。
▶︎ダウンロード先
以下は、両方のノートブックのすべてのセルが実行されると作成される、デフォルトのディレクトリです(提供されているままのものです)。ある本の中のどのページに挿絵が含まれているかのリストを取得した後、HTとIAのダウンロード機能はこれらのページをJPEG(ファイル名はページ番号)としてダウンロードして、それらをサブディレクトリ(名前は資料ID)に保存します。もちろん、異なる書籍リストを用いたり、出力先out_dirをitems以外のものに変えたりすることも可能です。
items/ ├── hathitrust │ ├── hvd.32044021161005 │ │ ├── 103.jpg │ │ └── ... │ └── osu.32435078698222 │ ├── 100.jpg │ ├── ... └── internetarchive └── talespeterparle00goodgoog ├── 103.jpg └── ... 5 directories, 113 files
ダウンロード機能はいい加減(lazy)で、上記のようにitemsのディレクトリを表示した状態でノートブックを再度実行すると、すでに自分のサブフォルダを持っているアイテムはすべてスキップされます。もしitemsディレクトリが上記のような場合にノートブックを再び実行すると、すでにサブフォルダがあるアイテムの処理はスキップされます。
Anaconda(オプション)
Anacondaとは、科学計算用のPythonディストリビューションとして主要なものです。このパッケージマネージャcondaで、numpyやtensorflowなどのライブラリを簡単にインストールすることが可能にになります。「Miniconda」バージョンには余計なパッケージがプリインストールされていないので、基本環境をクリーンに保ち、プロジェクトに必要なものだけを名前のついた環境にインストールすることができます。
Minicondaをダウンロードしてインストールします。Python 3の最新の安定版を選択します。すべてがうまくいけば、シェルでwhich conda (Linux/macOSの場合)、または、where conda (Windowsの場合)を実行すると、出力で実行可能なプログラムの場所を確認できるはずです
Anacondaにはよく使われるコマンドの便利なチートシートがあります。
▶︎環境設定
環境は、複数のパッケージマネージャを同時に使用する際の複雑さをコントロールするのに特に役立ちます。すべてのPythonライブラリがcondaを通じてインストールできるわけではありません。いくつかのケースでは、Pythonの標準パッケージマネージャであるpip(あるいはpipenvのような代替品)を頼ることになるでしょう。しかし、そうする場合は、condaによりインストールされたpipを使用します。これにより、プロジェクトに必要なすべてのパッケージを同じ仮想サンドボックスに入れておくことが出来ます。
# あなたの現在の環境は、前のアスタリスクで示されています。 # (新しいシェルでは "ベース "になります) conda env list # installed packages in the current environment conda list
次に、名前の付いた環境を作成し、Python 3を使うように設定して、開始します。
# --nameフラグは文字列の引数を取ること (例: "extract-pages")と # Python のバージョンを指定するための構文に注意してください conda create --name extract-pages python=3 # 新しい環境に入る (macOS/Linux) source activate extract-pages
# 環境を起動するためのWindowsコマンドが若干異なります conda activate extract-pages
環境から終了するには、macOS/Linuxではsource deactivateを、Windowsではdeactivateを実行してください。ただし、レッスン中はextract-pages環境にいることを確認してください!
▶︎Condaパッケージのインストール
最初のいくつかのパッケージはcondaを使ってインストールできます。他の必要なパッケージ(gzip、json、os、sys、time)はPython標準ライブラリの一部です。チャンネルを指定する必要があることに注意してください。Anaconda Cloudでパッケージを検索することができます。
# ローカルバージョンの pip があることを確認します (以下の説明を参照してください) conda install pip conda install jupyter conda install --channel anaconda requests
Jupyterには多くの依存関係(必要とする他のパッケージ)があるため、このステップには数分かかる場合があります。condaがProceed ([y]/n)?という表示をだしたら、yまたはyesと入力してからEnterキーを押して、パッケージブランを受け入れることを覚えておいてください。
裏では、condaは必要なパッケージと依存関係がすべて互換性のある方法でインストールされることを確認するために動いています。
▶︎Pipパッケージのインストール
condaa環境を使用している場合は、ローカルバージョンのpipを使用するのがベストです。以下のコマンドで、/Miniconda/envs/extract-pages/Scripts/pipのような絶対パスを含むプログラムを出力していることを確認してください。
which pip
# Windowsでは"which"と同等 where pip
上の出力に2つのバージョンのpipがある場合、APIラッパーライブラリをインストールする際に「ローカル」環境のバージョンへのフルパスを入力してください。
pip install hathitrust-api pip install internetarchive
# *ローカルの*pip実行ファイルへの絶対パスを使用したWindowsの例 C:\Users\stephen-krewson\Miniconda\envs\extract-pages\Scripts\pip.exe install hathitrust-api internetarchive
Jupyter Notebook
Peter OrganisciakとBoris Capitanuの「HTRC Feature Readerを使ったPythonでのテキストマイニング」(Text Mining in Python through the HTRC Feature Reader)は、開発やデータ探索のためのノートブックの利点を説明しています。また、このページには、セルを効果的に実行する方法についても有益な情報が掲載されています。私たちは、Anacondaの最小限のバージョンをインストールしたので、コマンドラインからJupyterを起動する必要があります。(レッスンファイルを含むフォルダ内から)シェルでjupyter notebookを実行してください。
下の画面は、シェルでノートブックサーバを実行し、Jupyter ホームページでデフォルトのブラウザを起動すると。ホームページには、現在の作業ディレクトリにあるすべてのファイルが表示されます。
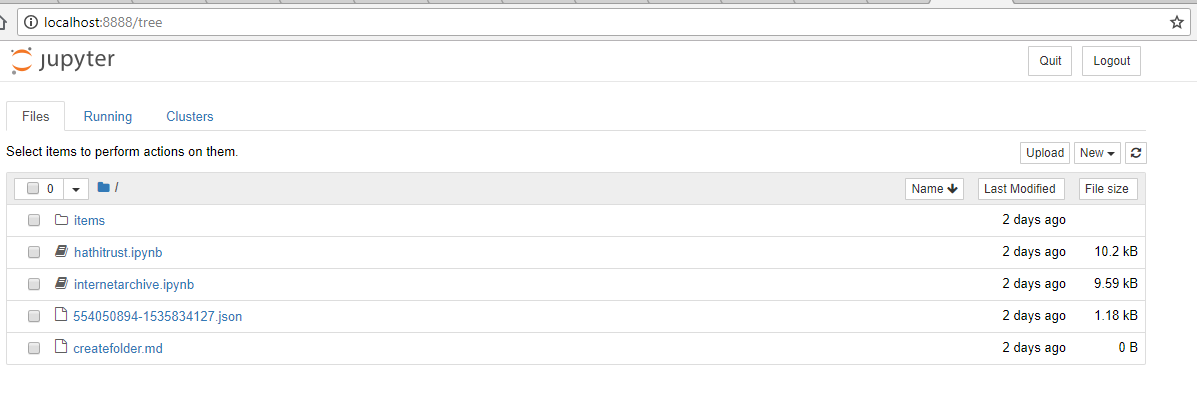
レッスンファイルを表示するJupyterホームページ
シェルで、解凍されたlesson-files ディレクトリにcdで移動していることを確認すること。
hathitrust.ipynbとinternetarchive.ipynbのノートブックをクリックして、新しいブラウザタブを開きます。ここからは、シェルのコマンドを実行する必要はありません。ノートブックのおかげで、Pythonのコードを実行でき、コンピュータのファイルシステムへフルアクセスができるようになりました。終了したら、Jupyterホームページの「Quit」をクリックするか、シェルでctrl+cを実行することで、ノートブックサーバを停止することができます。
HathiTrust
APIアクセス
データAPIを使う前に、HathiTrustに登録する必要があります。登録ポータルで、名前、組織名、メールアドレスを入力してアクセスキーをリクエストしてください。数分でメールの返信が届きます。リンクをクリックすると、2つのキーが表示されたワンタイムのページにアクセスします。
hathitrust.ipynbノートブックで、最初のセル(下記)を調べてください。指示通りにAPIトークンを入力します。そして、ノートブックのナビゲーションバーで「Run」をクリックすることでセルを実行します。
# HT Data APIラッパーのインポート from hathitrust_api import DataAPI # プレースホルダの文字列をHTの資格情報に置き換えてください(引用符は残してください) ht_access_key = "YOUR_ACCESS_KEY_HERE" ht_secret_key = "YOUR_SECRET_KEY_HERE" # Data API 接続オブジェクトのインスタンスを作成します。 data_api = DataAPI(ht_access_key, ht_secret_key)
注意!アクセストークンを GitHub (または他のバージョン管理ホスト) の公開レポで公開しないでください。誰でも検索できるようになってしまいます。Python プロジェクトでの良い方法は、トークンを環境変数として保存するか、バージョン管理されていないファイルに保存することです。
資料リストの作成
HTでは、ログインしていなくても、誰でも資料コレクションを作ることができます!ただし、資料リストを保存したい場合は、アカウント登録をする必要があります。指示に従って、いくつか全文検索を行い、選択した結果をコレクションに追加します。現在、HathiTrustでは、プログラムで書籍を取得するための検索用APIが公開されていないため、ウェブインターフェイスで検索する必要があります。
コレクションを更新すると、HTはコレクション内の各資料に関するメタデータを追跡します。レッスンファイルには、JSON形式のサンプルレッスンのメタデータが含まれています。もしあなた自身のHTコレクションのファイルを使いたい場合は、コレクションページに移動して、左側にあるメタデータのリンクの上にカーソルを置くと、下のスクリーンショットにあるようにJSON形式でダウンロードするオプションが表示されます。
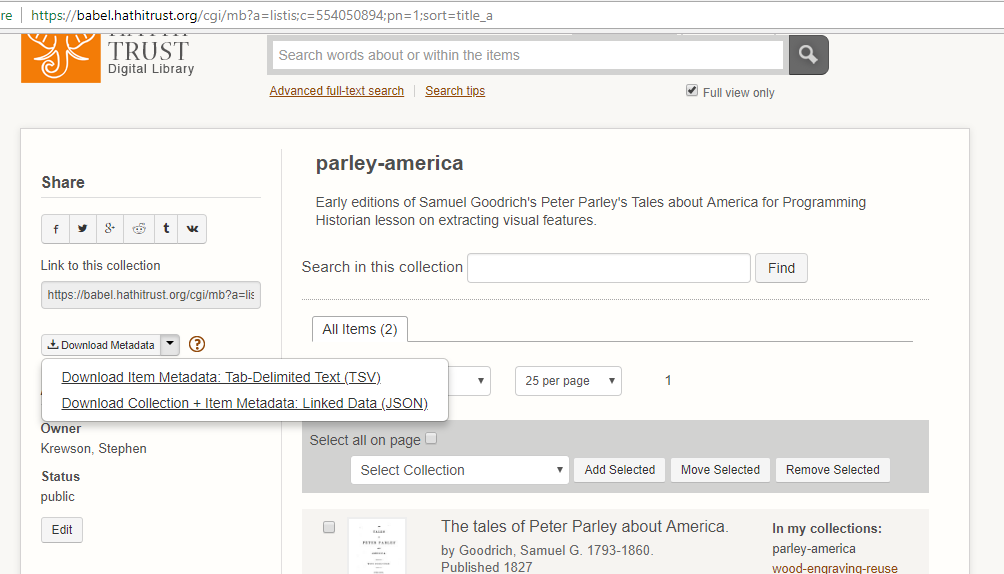
JSON ファイルをダウンロードしたら、Jupyter Notebookを配置したディレクトリに移動するだけです。HTノートブック内のJSONファイルの名前を、コレクションのファイル名に置き換えてください。
このノートブックでは、リスト内包表記を使い、コレクションの全情報を含むgathersオブジェクト内にある全てのhtitem_id文字列を得る方法を示しています。
# ここでコレクションのメタデータファイルを指定することができます。 metadata_path = "554050894-1535834127.json" with open(metadata_path, "r") as fp: data = json.load(fp) # コレクション内のすべてのユニークIDのリスト vol_ids = [item['htitem_id'] for item in data['gathers']]
他のチュートリアルでは、1つのアイテムをどのように処理するかを示すものがしばしばです(サイズは小規模のものや複雑なものが多いです)。教育的には便利ですが、これでは複数のアイテムにコードを適用する方法が身につきません。このノートブックでは、1つのアイテムに適用する変換方法を、アイテムのコレクションのループ内で呼び出すことができる「関数」にカプセル化する方法を見ていきます。
視覚的な特徴:IMAGE_ON_PAGE
資料リストがあると、ページレベルでどのような視覚的な特徴があるのかを探ってみたくなるだろう。(HTの)データAPIの最新ドキュメント(2015)では、9~10ページ目にhtd:pfeatと呼ばれるメタデータオブジェクトについて記述されています。htd:pfeatは「HathiTrustデータAPI:ページの特徴」の略です。
· htd:pfeat - the page feature key (if available):
o CHAPTER_START
o COPYRIGHT
o FIRST_CONTENT_CHAPTER_START
o FRONT_COVER
o INDEX
o REFERENCES
o TABLE_OF_CONTENTS
o TITLE
hathitrust-apiラッパーが行うのは、HT資料の全メタデータをPythonオブジェクトとして利用できるようにすることです。資料の識別子があれば、そのメタデータをリクエストして、ページシーケンスからページレベルまで情報を掘り下げることができます。htd:pfeatの「リスト」は本の各ページに対応しており、理論的にはそのページに当てはまる全ての特徴を含んでいます。実際には、上に挙げた8つの特徴タグよりもかなり多くのタグがあります。私達が扱うことになるのは、IMAGE_ON_PAGEと呼ばれるもので、CHAPTER_STARTのような構造タグよりも抽象的で視覚的なものになります。
ミシガン大学図書館の研究司書のTom Burton-Westは、HathiTrustとHathiTrust研究センター(HTRC)と緊密に連携をしています。Tomは私に、HathiTrustが2008年のHT設立以来、密接に連携しているGoogleから、htd:pfeatの情報を提供されているとメールで教えてくれました。Googleの担当者はTomに以下の情報を共有する許可を与えてくれました。
これらのタグは、ヒューリスティック、機械学習、人間によるタグ付けの組み合わせで作成されたものです。
ヒューリスティックの例としては、資料のページシーケンスの最初の要素がほぼ常にFRONT_COVERだと考えられます。機械学習は、例えば洋書の散文や彫刻に彫られる典型的な数行と画像データとを識別するためのモデルを訓練するために使用することができます。人によるタグ付けは、手動で画像にラベルを割り当てることです。EEBOやECCOなどのデータベースで挿絵が見られるのは、人間によるタグ付けの例です。
Googleが「機械学習」を使ったというのは少し不思議な感じがします。Googleがその手法公開するまで、すべての詳細を知ることは不可能です。しかしIMAGE_ON_PAGEタグは、OCR出力ファイルから「Picture」ブロックを検出することで最初に提案された可能性が高いです(この仮説については、後述するInternet Archiveの節で説明します)。その後、さらなるフィルタリングが適用されているのかもしれません。
コード・ウォークスルー
▶︎画像を見つける
ここまで、書籍リストを作成する方法と、データAPIを使ってページレベルの経験的な特徴を含むメタデータオブジェクトを取得する方法を見てきました。HTノートブックのコア関数は、ht_picture_download(item_id, out_dir=None)というシグネチャがあります。ユニークな識別子とオプションの保存先ディレクトリを与えると、この関数はまずAPIから書籍メタデータを取得し、JSON形式に変換します。次にページシーケンスをループし、(もしあれば)IMAGE_ON_PAGEタグがhtd:pfeatリストにあるかどうかを確認します。
# APIからのメタデータをjson形式で読み込む(HTコレクションのメタデータとは異なる) meta = json.loads(data_api.getmeta(item_id, json=True)) # シーケンスは、スキャンされたアイテムの各ページを順番に取得し、追加情報があればそれも含める sequence = meta['htd:seqmap'][0]['htd:seq'] # 挿絵ページを格納するための空のリストを作成 img_pages = [] # try/exceptブロックは"pfeats"が存在しない場合、あるいは、シーケンス番号が数値でない場合を処理するものです for page in sequence: try: if 'IMAGE_ON_PAGE' in page['htd:pfeat']: img_pages.append(int(page['pseq'])) except (KeyError, TypeError) as e: continue
トップレベルのオブジェクトから数段階掘り下げないと、反復処理を行えるhtd:seqオブジェクトに辿り着けないことに注意してください。
捕まえたい2つの例外は、ページにページレベルの特徴がない場合に起こるKeyErrorと、何らかの理由でページのpseqの値が非数値型のためにint型に変換できない場合に起こるTypeErrorです。ページでなにかおかしなことが起こった場合には、次のページにcontinueするだけです。考え方としては、できる限りの良いデータを取得することにあります。アイテムのメタデータの不整合やギャップをきれいにするためではありません。
▶︎画像をダウンロードする
img_pagesにIMAGE_ON_PAGEでタグ付けされたページの完全なリストが含まれていれば、それらのページをダウンロードできます。ht_picture_download()にout_dirが指定さてれない場合、この関数は単にimg_pagesのリストを返し、なにもダウンロードしないことに注意せよ。
APIコールgetpageimage()は、デフォルトでJPEGを返します。通常の方法で、単にJPEGのバイト配列をファイルに書き出すだけです。(out_dir内の)資料サブフォルダ内では、1ページ目は1.jpgというように名前を付けられます。
考慮すべきは、APIの使用率です。1分間に何百ものリクエストをしてアクセスを悪用することは避けたいものです。安全のために、特に大きなジョブを実行する場合は、各ページのリクエストを行う前に2秒待ちます。これは短期的にはイライラするかもしれませんが、APIのスロットルや使用停止を回避することに役立ちます。
for i, page in enumerate(img_pages):
try:
# 簡単な処理状況の確認メッセージの出力
print("[{}] Downloading page {} ({}/{})".format(item_id, \
page, i+1, total_pages))
img = data_api.getpageimage(item_id, page)
# 注意:out_dir が None ではない場合にのみループは実行されます。
img_out = os.path.join(out_dir, str(page) + ".jpg")
# 画像を書き出す
with open(img_out, 'wb') as fp:
fp.write(img)
# API利用停止の回避するために2秒間を挟む
time.sleep(2)
except Exception as e:
print("[{}] Error downloading page {}: {}".format(item_id, page,e))
Internet Archive
APIアクセス
APIトークンではなく、Archive.orgのアカウントのメールとパスワードを使って、Python APIライブラリに接続します。これについては、クイックスタートガイドで説明しています。アカウントを持っていない場合は、「仮想図書館カード(“Virtual Library Card”)」に登録してください。
internetarchive.ipynbノートブックの最初のセルに、指示されたとおりに、資格情報を入力します。APIへの認証を行うためにセルを実行します。
資料リストの作成
IAのPythonライブラリを使用してクエリ文字列を送信すると、”identifier”(識別子)という単語がキーで実際の識別子がデータ値となる、キーと値のペアのリストを受け取ることができます。クエリの構文については、IAの高度検索ページで説明しています。”date”(日付)、”mediatype”(メディアタイプ)のようなキーワードの後にコロンを続け、そのパラメータに割り当てたい値を指定します。例えば、私は(動画などではなく)「テキスト」の結果だけを表示したいです。使用しようとするパラメータとオプションがIAの検索機能でサポートされていることを確認してください。そうしないと、欠けていたりや奇妙な結果が得られ、また、その理由が分からなくなる可能性があります。
ノートブックでは、私はIAのIDリストを生成しています。:
# サンプル検索(2つの結果が得られます) query = "peter parley date:[1825 TO 1830] mediatype:texts" vol_ids = [result['identifier'] for result in ia.search_items(query)]
視覚的な特徴:Pictureブロック
Internet Archiveはページレベルの特徴は一切公開していません。その代わりに、デジタル化の過程で得られた多くの生のファイルをユーザーが利用できるようにしています。私達の目的に最も重要なのは、Abbyy XMLファイルです。Abbyy社はロシアの企業で、FineReaderというソフトウェアはOCR市場を席巻しています。
FineReaderの最近のバージョンはすべて、スキャンした文書の各ページに、異なる「ブロック」を関連付けるXML文書を生成しています。最も一般的なブロックはTextですが、Pictureブロックもあります。ここでは、IAのAbbyy XMLファイルから取り出したブロックの例を示します。左上(「t」と「l」)と右下(「b」と「r」)の隅で、十分長方形のブロック領域を特定できます。
<block blockType="Picture" l="586" t="1428" r="768" b="1612"> <region><rect l="586" t="1428" r="768" b="1612"></rect></region> </block>
HTでIMAGE_ON_PAGEタグを探すのと同等のIAでの方法は、Abbyy XMLファイルを解析し、各ページの反復処理をすることです。そのページに1つでもPictureブロックがあれば、そのページは画像が含まれている可能性があるというフラグが立てられます。
HTのIMAGE_ON_PAGEの特徴では画像の「位置」についての情報は含まれていないが、XMLファイルのPictureブロックはページ上の長方形の領域に関連付けられている。しかしFineReaderは西洋の文字セットからの文字を認識することに特化しているので、画像の領域を特定する精度ははるかに低い。Leetaruのプロジェクト(「概要」を参照)では、座標を使って挿絵をトリミングしていましたが、このレッスンでは単にページ全体をダウンロードすることにしました。
このレッスンの知的な楽しみの一つは、ノイズの多いデータセット(つまり、OCRのブロックタグ)を、単語ではなく挿絵を認識するために利用するという、意図されていない目的のために使うことにあります。将来的には、書籍内の全てのページ画像にディープラーニングモデルを実行し、希望するタイプの挿絵を選び出すことがコンピュータで可能になるでしょう。しかし、ほとんどの資料のほとんどのページには挿絵がないため、これは計算コストのかかる作業です。今のところは、OCRの認識過程から得られた既存データを活用する方が理に適っています。
OCR自体がどのように動作し、スキャンプロセスと相互作用するかについての詳細は、Mila OivaのProgramming Historianのレッスン「OCR with Tesseract and ScanTailor」を参照してください。エラーは、ゆがみや人為的な影響など多くの問題によって生じえます。これらのエラーは、結果的に「Picture」ブロックの信頼性と精度に影響を与えることになります。多くの場合、Abbyyは空白ページや変色したページを挿絵(画像領域)だと推定します。これらの不正確なブロックタグは望ましくないものですが、再訓練させた畳み込みニューラルネットワークによって処理することができます。このレッスンでダウンロードするページ画像は、クリーンで利用可能な歴史的な挿絵データセットを得るための長いプロセスの最初の段階と考えるようにしてください。
コード・ウォークスルー
▶︎画像を見つける
HTと同様、IAのコア関数はia_picture_download(item_id, out_dir=None)です。
これはファイルの入出力を伴うので、img_pagesリストを得るにはHTの場合より複雑です。(ライブラリと共にインストールされる)コマンドラインユーティリティのiaを使うと、資料に関する利用可能なメタデータファイルを知ることができます。Iごく少数の例外を除いて、Internet Archive上のメディアタイプのテキストを持つボリュームでは、フォーマットが「Abbyy GZ」のファイルが利用できるはずです。
これらのファイルは、たとえ圧縮されていたとしても、簡単に数百メガバイトのサイズになることがあります。ボリュームにAbbyyファイルがあれば、その名前を取得してダウンロードします。ia.download()コールでは、ファイルが既に存在する場合はリクエストを無視し、存在しない場合は入れ子になったディレクトリを作らずにダウンロードするための便利なパラメータを使用しています。容量を節約するために、ファイルを解析した後に Abbyy ファイルを削除しています。
# 利用可能なメタデータフォーマットを確認するため、コマンドラインクライアントを使用します。:
# `ia metadata formats VOLUME_ID`
# このレッスンではAbbyyファイルだけが必要です。
returned_files = list(ia.get_files(item_id, formats=["Abbyy GZ"]))
# 何かしら返されたことを確認します
if len(returned_files) > 0:
abbyy_file = returned_files[0].name
else:
print("[{}] Could not get Abbyy file".format(item_id))
return None
# AbbyyファイルをCWDへダウンロードします
ia.download(item_id, formats=["Abbyy GZ"], ignore_existing=True, \
destdir=os.getcwd(), no_directory=True)
ファイルを取得したら、Pythonの標準ライブラリを使ってXMLを解析する必要があります。圧縮ファイルをgzipライブラリで直接開けられることを利用します。Abbyyファイルは0オリジン(zero-indexed)のため、スキャンシークエンスの最初のページのインデックスは0となっています。しかし、0ではIAからリクエストできないため、0を除去しなければなりません。IAが0インデックスを除外することは、どこにも書かれておらず、私はこれを試行錯誤で発見しました。もしあなたが説明しにくいエラーメッセージが表示されたら、ソースを探し出して、似た経験のある人や組織自体に助けを求めることを恐れないでください。
# 少なくとも1つの画像ブロックを持つページを収集する img_pages = [] with gzip.open(abbyy_file) as fp: tree = ET.parse(fp) document = tree.getroot() for i, page in enumerate(document): for block in page: try: if block.attrib['blockType'] == 'Picture': img_pages.append(i) break except KeyError: continue # 0はIAへのGETリクエストを行うための有効なページではありませんが、# 時々Abbyyの圧縮ファイルにあります img_pages = [page for page in img_pages if page > 0] # ダウンロードの進行状況のトラッキングのための処理 total_pages = len(img_pages) # OCRファイルは巨大なので、ページリストができたら削除してください。 os.remove(abbyy_file)
▶︎画像をダウンロードする
IAのPythonラッパーは、複数ページのダウンロードのみが可能で、単一ページのダウンロード機能は提供していません。つまり、IAのRESTful APIを使って特定のページを取得することになります。まず、必要なページごとのURLを構築します。そしてrequestsライブラリを使ってHTTPのGETリクエストを送り、うまくいけば(つまりレスポンスでコード200が返ってくるなどすれば)、レスポンスの内容をJPEGファイルに書き出します。
IAは、国際的な画像相互運用のためのフレームワークであるIIIF(International Image Interoperability Framework)に準拠した画像のトリミングとサイズ変更のためのAPIのアルファ版に取り組んできました。ほとんどサポートされていない形式で、JP2ファイルのダウンロードを必要としていた単一ページダウンロードの古い方法と比べ、IIIFは大きな改善をもたらしました。今では、シングルページのJPEGを取得するのは非常に簡単です。
# https://iiif.archivelab.org/iiif/documentationを見よ urls = ["https://iiif.archivelab.org/iiif/{}${}/full/full/0/default.jpg".format(item_id, page) for page in img_pages] # pythonライブラリを介して直接ページをダウンロードせず、GETリクエストを構築する for i, page, url in zip(range(1,total_pages), img_pages, urls): rsp = requests.get(url, allow_redirects=True) if rsp.status_code == 200: print("[{}] Downloading page {} ({}/{})".format(item_id, \ page, i+1, total_pages)) with open(os.path.join(out_dir, str(page) + ".jpg"), "wb") as fp: fp.write(rsp.content)
この後のステップ
ノートブックの主要な関数とデータを取り出すためのコードを理解したら、セルを順番に実行したり、あるいは「Run All」をしたりして、挿絵ページが入ってくるのを自由に見てみましょう。これらのスクリプトや関数は、あなた自身の研究課題に合わせて活用することをお勧めします。
著者について
Stephen Krewsonはイェール大学の英文学博士課程に在籍し、19世紀初期の進歩主義的教育理論と印刷メディアの間の相互作用について研究をしています。彼はコンピュータサイエンスの修士号を持ち(同じくイェール大)、大規模な電子図書館におけるフィルタリングや検索作業の効率化手法の開発も行っています
引用の際はこちらをご利用ください
<原著>
Stephen Krewson, “Extracting Illustrated Pages from Digital Libraries with Python,” The Programming Historian 8 (2019), https://programminghistorian.org/en/lessons/extracting-illustrated-pages.
<翻訳記事>
Stephen Krewson著, 菊池信彦訳. Pythonを使って電子図書館から挿絵のページを抽出する. 東アジアDHポータル. 2020. https://www.dh.ku-orcas.kansai-u.ac.jp/?p=390.

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。